一、URL 设计
1.1 动词 + 宾语
RESTful 的核心思想就是,客户端发出的数据操作指令都是”动词 + 宾语”的结构。比如,GET /articles这个命令,GET是动词,/articles是宾语。
动词通常就是五种 HTTP 方法,对应 CRUD 操作。
- GET:读取(Read)
- POST:新建(Create)
- PUT:更新(Update)
- PATCH:更新(Update),通常是部分更新
- DELETE:删除(Delete)
根据 HTTP 规范,动词一律大写。

Posted on 10 10 月 2018 by simon
RESTful 的核心思想就是,客户端发出的数据操作指令都是”动词 + 宾语”的结构。比如,GET /articles这个命令,GET是动词,/articles是宾语。
动词通常就是五种 HTTP 方法,对应 CRUD 操作。
- GET:读取(Read)
- POST:新建(Create)
- PUT:更新(Update)
- PATCH:更新(Update),通常是部分更新
- DELETE:删除(Delete)
根据 HTTP 规范,动词一律大写。
Posted on 10 5 月 2017 by simon
到底该用哪个接口,微软这么说,api方式:功能齐全,不过调用复杂些;com接口,调用简单,属于一个封装,有部分功能缺失。https://msdn.microsoft.com/zh-cn/library/aa383158(v=vs.85).aspx
| C/C++ API | COM interface | |
|---|---|---|
| Advantages |
|
|
| Disadvantages |
|
|
Posted on 09 4 月 2014 by simon
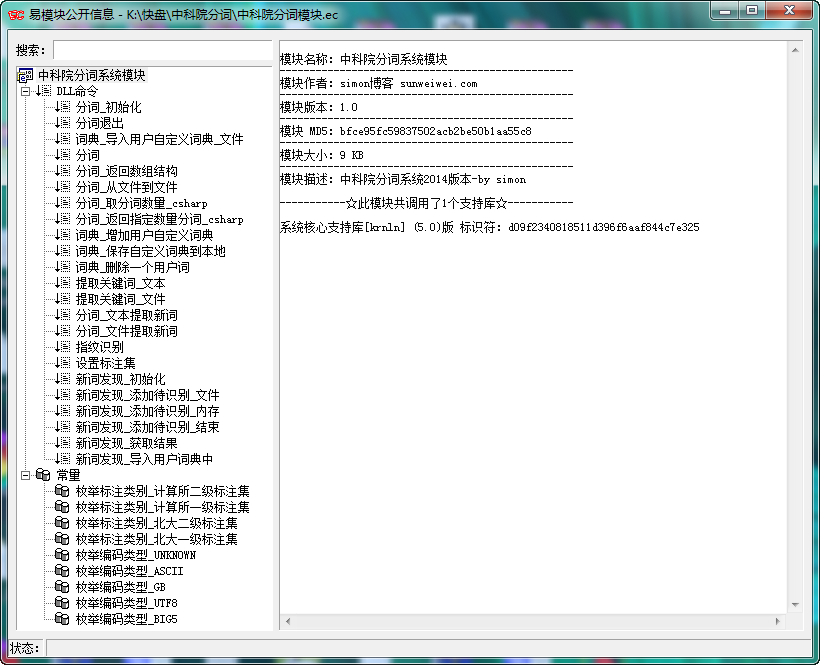
NLPIR汉语分词系统(官网:http://ictclas.nlpir.org/)
NLPIR汉语分词系统(又名ICTCLAS2014),主要功能包括中文分词;词性标注;命名实体识别;用户词典功能;支持GBK编码、UTF8编码、BIG5编码。新增微博分词、新词发现与关键词提取。
中科院的NLPIR分词系统应该是目前公认做的比较好的,支持自定义词典、支持批量分词、关键词提取、词性标注、文章指纹识别,2014版本添加了新词(未登录词)的识别等。
之前因为准备用里面的一个接口,找了一番发现其官方并没有提供易语言的api接口文档及源码示例。。。很多人对NLPIR分词系统还是很有需求的,所以制作了一个易语言的模块,封装了最新2014版的所有接口以供调用。
1、关键词提取接口:NLPIR_GetKeyWords()、NLPIR_GetFileKeyWords()这两个接口,分别为从文本中提取关键词和从文件中提取关键词,支持指定数量的提取和TF/IDF权重的输出,用来做tag标签啥的,比较合适。
2、指纹识别接口:NLPIR_FingerPrint()返回的貌似是一个多维度十六进制的向量,可以用在检测文章相似度上面,比如计算两篇文章指纹向量的余弦相似度;或者对采集的多个文件进行去重等等。而且这个分词系统支持多线程,大批量运行应该没太大问题。
3、新词识别接口:除自己定义的词典,此接口支持将识别到的新词自动导入到自定义词典中。里面新词识别接口有2个,建议使用后添加的NLPIR_NWI_Start() API.
4、关于用户词典和核心词典中同时有的分词词汇,谁优先? 可以在data/Configure.xml中设置
中科院分词模块.ec 下载地址: http://pan.baidu.com/s/1mgqMfrE 密码: h1a5
模块使用很简单:
1、去官方下载通用的NLPIR/ICTCLAS2014分词系统下载包(2014.3.24发布的),并解压到本地,只需要里面的NLPIR.dll(要找一下)和data目录文件即可
2、之后直接用易语言调用模块即可,如果不会用模块调用,请注意看模块里的每个参数说明,或查看官方的接口文档说明。

