——————————update 2018.4——————————————
已招到!
——————————update 2017.11——————————————
还缺一人。。
We Need You!
发一则招聘,南京地区
招SEO,比较着急。
公司:house365
人数:1
要求:一年以上SEO工作经验
大站SEO操作的机会来了,筒子们有简历请发simonsww@qq.com,注明来自博客。

Posted on 10 10 月 2017 by simon
——————————update 2018.4——————————————
已招到!
——————————update 2017.11——————————————
还缺一人。。
发一则招聘,南京地区
招SEO,比较着急。
公司:house365
人数:1
要求:一年以上SEO工作经验
大站SEO操作的机会来了,筒子们有简历请发simonsww@qq.com,注明来自博客。
Posted on 19 5 月 2014 by simon
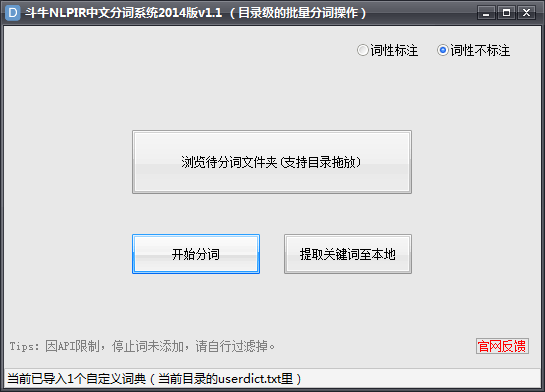
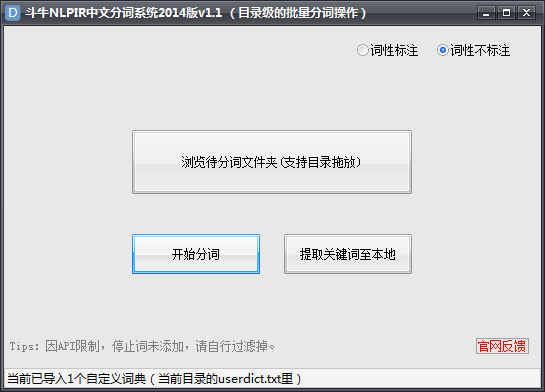
斗牛NLPIR中文分词工具V1.1已发布,本分词工具采用NLPIR2014最新版。可直接对文件夹里所有文件自动分词,提取关键词(包括对未登录词的识别),支持词性标注及自定义词典。
1、支持对目录级别的所有文件直接批量分词
2、支持批量提取多个文件里的关键词,带权重值输出(此值非TF-IDF,而是交叉熵),包含新词(未登录词)识别等
3、支持分词结果的词性标注,如人名、地名、机构名、数词、时间词等等。
4、支持用户自定义词典,在\dat\userdict.txt里添加
1、将待分词的文本都放入到一个文件夹中
2、直接拖动文件夹至软件窗口或浏览到对应目录
3、点开始运行或提词。
温馨提示:待分词的文本编码需为ANSI,否则可能会出现乱码的情况。可用notepad++打开后,右下角状态栏提示编码。
软件下载: www.douniu.la 已集成至斗牛SEO工具中!
Posted on 17 5 月 2014 by simon
斗牛SEO工具VIP版V11.1发布了 -SEOer的瑞士军刀!
斗牛SEO官网:www.douniu.la 官方售卡系统(全自动发货):http://www.douniu.la/sale.php
![]()
[VIP开通流程]:去官方的售卡系统购买注册卡(目前为三种,季卡、半年卡、年卡),然后下载软件,在软件界面注册开通VIP账号,有疑问可联系客服QQ:604886421
购买VIP后可进入斗牛SEO工具高级群!
公开QQ群:145876858 106983747
写在前面:实行付费功能后,斗牛SEO工具VIP版进入常态化更新,保证一直可用;同时斗牛SEO工具包含的会越来越多,不仅仅是目前的这些工具,会根据作者本人或大家的工作需求等等因素,陆续发布上来,成为VIP后可一直使用,绝对是目前性价比最高的SEO工具。
所有软件全部采用数字签名的方式发布,可以通过右键–属性–数字证书查看到作者信息。如果没有相应信息的,一律为破解版,相应大家能够辨识吧。
工具收费的目的是为了能够让斗牛延续下去,否则实在是没精力更新了,当然收费也是极低的。。。
备注:VIP版即使不付费也可以使用大部分功能,不过查询数量上会有所限制,具体请参照软件说明,VIP则无任何限制。
目前发布的是11个工具,故VIP版本号从11开始。。。
一、【关键词排名批量查询工具】
升级至V7.1
1、网页访问方式更改为curl
2、添加自动换ip功能,如遇验证码会随机选择一条代理ip
3、添加一词对应一个URL查询模式,即外推专用版,免费用户有查询数量限制
4、改善界面底部的TOP数字长度
5、修复之前6.2版本的bug,及功能改进等等
二、【URL收录批量查询工具】
升级至V4.0
1、网页访问方式更改为curl
2、添加自动换ip功能,如遇验证码会随机选择一条代理ip
3、修复3.2版本的小bug
三、【百度竞价长尾词拓展工具】
升级至V4.0
1、添加长尾词必须包含种子词的功能
2、添加获取结果实时写入到本地文件的功能,尤其适合对大量数据的长时间采集,免费版无此功能。
四、【百度商情长尾词拓展工具】
升级至V3.0
1、添加提取指数功能,获取的长尾词自带指数数据,免费版无此功能。
2、完善获取结果实时写入到本地文件的功能,方便大数据量处理。
五、【爱站关键词工具】
升级至V4.0
1、网页访问方式更改为curl
2、添加自动换ip功能,如遇验证码会随机选择一条代理ip
3、部分功能的优化
六、【中文分词工具NLPIR】
升级至V1.1,免费用户无法使用
分词工具采用NLPIR2014最新版
1、支持对目录级别的所有文件直接批量分词
2、支持批量提取多个文件里的关键词,带权重值输出(此值非TF-IDF,而是交叉熵),包含新词(未登录词)识别等
3、支持分词结果的词性标注,如人名、地名、机构名、数词、时间词等等。
4、支持用户自定义词典,在\dat\userdict.txt里添加
七、【http状态码批量查询工具】
升级至V3.0
1、网页访问方式更改为curl
2、修改内部访问逻辑,提高查询效率,及提升稳定性
八、【PR/SR/BR批量查询工具】
升级至V3.0
1、完善返回数据可能为空的情况
九、【页面URL一键提取器】
升级至V3.1
1、添加常用正则的选择列表,更简单易用
十、【百度SERP标题描述预览工具】
升级至V2.0
1、修复之前版本的失效问题
2、添加了百度SERP结果位置的上下移动功能,可对比竞争对手的预览展示
3、去掉了对谷歌的预览功能,基本无人使用
十一、【文章原创度批量检测工具】
升级至V1.1
1、小幅更新,修复针对单篇文章的检测,当提取字段数为0时,会发生崩溃的现象。
十二、【百度指数批量查询工具】
升级至V4.0
因时间问题,暂未添加上,下个版本加上。
Posted on 09 4 月 2014 by simon
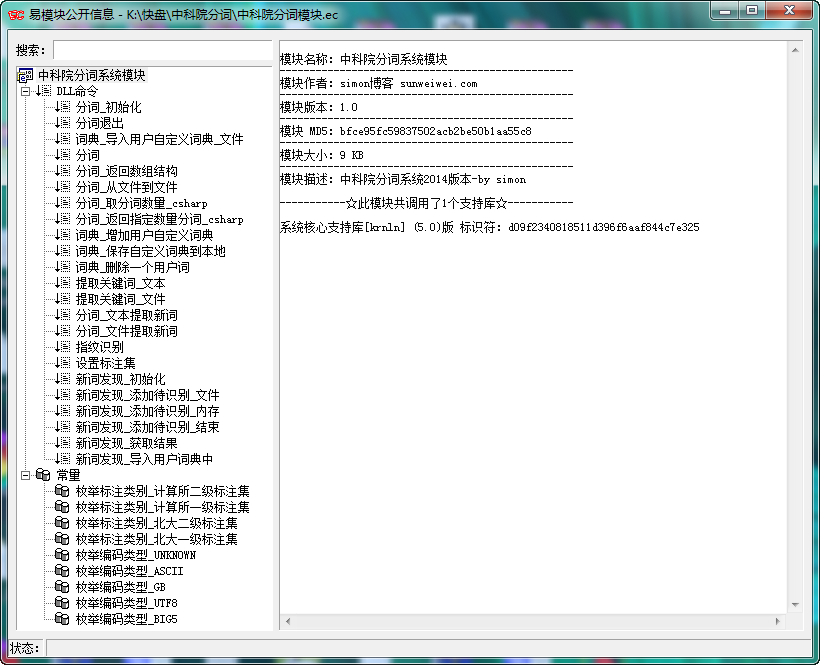
NLPIR汉语分词系统(官网:http://ictclas.nlpir.org/)
NLPIR汉语分词系统(又名ICTCLAS2014),主要功能包括中文分词;词性标注;命名实体识别;用户词典功能;支持GBK编码、UTF8编码、BIG5编码。新增微博分词、新词发现与关键词提取。
中科院的NLPIR分词系统应该是目前公认做的比较好的,支持自定义词典、支持批量分词、关键词提取、词性标注、文章指纹识别,2014版本添加了新词(未登录词)的识别等。
之前因为准备用里面的一个接口,找了一番发现其官方并没有提供易语言的api接口文档及源码示例。。。很多人对NLPIR分词系统还是很有需求的,所以制作了一个易语言的模块,封装了最新2014版的所有接口以供调用。
1、关键词提取接口:NLPIR_GetKeyWords()、NLPIR_GetFileKeyWords()这两个接口,分别为从文本中提取关键词和从文件中提取关键词,支持指定数量的提取和TF/IDF权重的输出,用来做tag标签啥的,比较合适。
2、指纹识别接口:NLPIR_FingerPrint()返回的貌似是一个多维度十六进制的向量,可以用在检测文章相似度上面,比如计算两篇文章指纹向量的余弦相似度;或者对采集的多个文件进行去重等等。而且这个分词系统支持多线程,大批量运行应该没太大问题。
3、新词识别接口:除自己定义的词典,此接口支持将识别到的新词自动导入到自定义词典中。里面新词识别接口有2个,建议使用后添加的NLPIR_NWI_Start() API.
4、关于用户词典和核心词典中同时有的分词词汇,谁优先? 可以在data/Configure.xml中设置
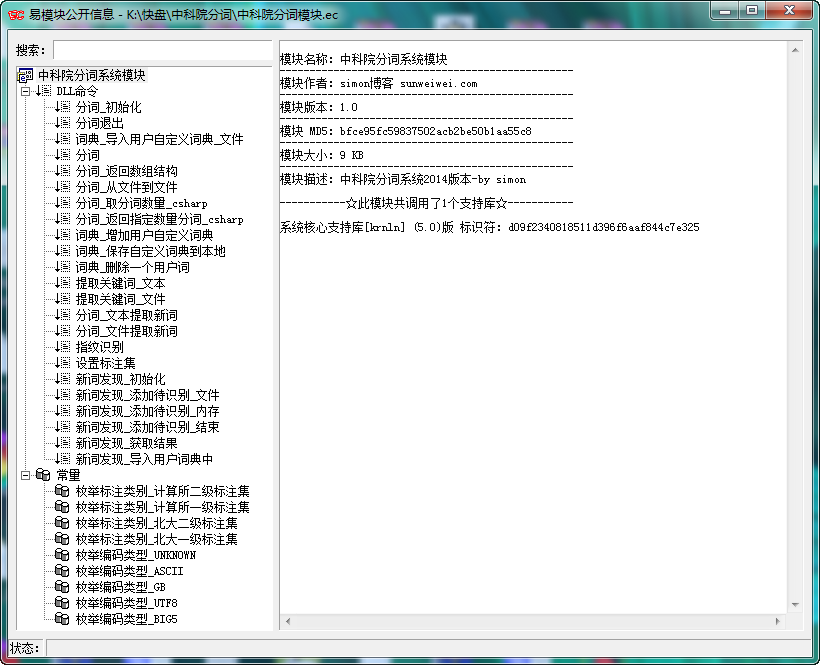
中科院分词模块.ec 下载地址: http://pan.baidu.com/s/1mgqMfrE 密码: h1a5
模块使用很简单:
1、去官方下载通用的NLPIR/ICTCLAS2014分词系统下载包(2014.3.24发布的),并解压到本地,只需要里面的NLPIR.dll(要找一下)和data目录文件即可
2、之后直接用易语言调用模块即可,如果不会用模块调用,请注意看模块里的每个参数说明,或查看官方的接口文档说明。

Posted on 24 1 月 2014 by simon
最近发现新浪SAE平台上竟然也提供分词功能,分词效果也还不错,由新浪爱问提供的分词服务,研究了一番,做了一个简易版的在线调用接口(get方式,非post)
官网说明:http://apidoc.sinaapp.com/class-SaeSegment.html,SAE分词系统基于隐马模型开发出的汉语分析系統,主要功能包括中文分词、词性标注、命名实体识别、新词识别。
调用规则:http://simonfenci.sinaapp.com/index.php?key=simon&wd={语句}
(返回结果里包含分词词性,随便用个程序语言处理一下就行了,详见:http://apidoc.sinaapp.com/class-SaeSegment.html#POSTAG_ID_UNKNOW)
只需要改变URL中的{语句}参数即可(编码为utf-8),因为是get方式传参,语句不能太长;也可以根据官方的api文档,做个简易的post方式。
另推荐几个分词系统:
1、Python的结巴中文分词系统(推荐),demo:http://jiebademo.ap01.aws.af.cm/ ,下载地址:https://github.com/fxsjy/jieba
2、中科院ICTCLAS中文分词系统,支持C/C#/C++/JAVA,32/64都有其对应的版本,有开发能力的可以尝试一下。
3、海量云分词系统demo ,分词效果也不错,可以申请到api接口,官网:http://www.hylanda.com/show_5_19.html
推荐阅读:
Posted on 06 5 月 2013 by simon
google chart 图表还是比较方便的,尤其是在利用api接口,生成图片形式,可以用来做数据统计分析,数据监控。
相关链接:
http://www.ruanyifeng.com/blog/2007/12/google_chart_api.html
http://www.haijd.net/archive/computer/google/google_chart_api/api.html
Google Chart API 参考 中文版
英文版版权归 Google , 转载此中文版必须以链接形式注明原文地址、译者信息及本声明。
API 参考:http://labs.cloudream.name/google/chart/api.html
常见问题:http://labs.cloudream.name/google/chart/faq.html
Google Chart API 为您提供动态创建图表的功能。单击下边的网址查看示例演示:
http://chart.apis.google.com/chart?cht=p3&chd=s:hW&chs=250×100&chl=Hello|World
您应该看到如下图表
Posted on 20 3 月 2013 by simon
此代码为自用log一键分析日志脚本,使用工具为Cygwin,各位可参照修改其中参数。
使用方法很简单:直接复制到Cygwin,回车执行,总体运行效率还是可以的,各个要素都有数据文件输出。
———一键代码 日志拆分by simon ——
更新日志:
3月18日:添加排除特征库代码(考虑到某些日志文件里会有很多干扰数据的原因)
1月5日:建立版本V1.0
—日志先清理##字符串,全部替换为空,用sed替换掉,代码如下
cat *>rz.log
sed -e ‘s/##/ /g;s/ 115.238.101.227//g;s/ 112.25.11.14,//g’ rz.log >rzql.log
[说明]:-e代表多个规则,s/X1/X2/g中为语法,X1为替换前字符串,X2为替换后,多个规则用;代替。
[我的log标准日志格式为,可自定义]:
123.125.71.77 – – [25/Dec/2013:00:01:17 +0800] “GET /URL HTTP/1.0” /database/webroot/showthread.php 200 11057 “-” “Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)” 172.17.1.101
特征库:(排除监控代码、局域网IP、服务器IP等)
– – – \[(.*?).*
.*jiance.php .*
42.121.107.149
112.25.11.14,
115.238.101.227
101.226.4.1.,
123.126.50.183,
123.151.42.48
172.17.1… #服务器局域网的IP范围匹配# Continue Reading
Posted on 14 10 月 2012 by simon
对于seo新手来说nofollow标签的概念可能比较模糊,片面化,不过我们需要做的就是明白此标签的意义以及如何使用它即可。
如一个链接代码为 <a href="signin.php" rel="nofollow">注册</a>
那么就告知搜索引擎不要去追踪这个链接,不抓取这个链接,且不传递PR值。
如果A网页上有一个链接指向B网页,但A网页给这个链接加上了 rel="nofollow" 标注,则搜索引擎不把A网页计算入B网页的反向链接。
nofollow标签怎么用?
如果需要对某个链接做nofollow:以下操作,即进行了 nofollow:
<a href="http://www.baidu.com/" rel="nofollow" >顶顶</a>
如果我们需要对整个页面所有链接做nofollow?
在页面的头部,里加上元标签 <meta name="robots" content="nofollow" /> 即可。
同时对于一些无排名需求的页面,我们都可以用nofollow来操作。

Posted on 18 9 月 2012 by simon
看到这个标题可能不少人是嗤之以鼻的,您还以为是90年代?~~不,今天我们讨论的是URL过多参数带来的次级影响,而非这个url本身.
URL中过多的参数是否会将google蜘蛛带入抓取死循环?
答案是肯定的,不过有一个前提,你的GA代码里的trackpageview开启了自定义页面(即虚拟页面)。
经过一段时间的研究发现,google确实会发生此种情况(百度对GA的JS应该是直接跳过的,根本不理睬~)。上次曾写过一篇此类的问题:关于GA代码里的trackPageview的url问题,代码404? 当时以为是因为格式符合的问题,目前看来不是那个问题,而是google自身的问题。
一般意义上,随着搜索引擎技术的发展,常规的url,即使有10多个参数,搜索引擎也是能够抓取的,没有错。百度和google都能做到。
可如果在这些URL拥有很多参数的页面里,JS的GA代码里trackpageview带有一个相对的地址(为了便于数据统计),那么google此时就开始犯傻了。不知道这是否是个bug?疯狂的抓取的这些不存在的页面,造成整个网站数量级上面的404页面,足足有18万之多,而且呈每日3000左右的递增,这让人情何以堪。。。
造成的影响就是,google蜘蛛抓取非常不稳定,收录,来访次数,来自google的流量等等都开始下降。。。
查阅了很多资料,根本找不到相关描述文档。
————————此处后期更新——————————
2013年1月最新更新:经过查阅相关资料,google对于此类页面是有抓取的,无法避免此缺陷
那么对我们目前来说,如何解决这个问题呢?
1、我们应该尽快将页面的动态形式更改为伪静态化后的,过多的参数也影响的蜘蛛抓取效率。
2、直接取消目前的自定义页面形式,采用默认的即可。(本人不建议此类操作,因为这样修改后,会造成数据缺失,前后数据无法衔接,无法统一分析,属于下下策,bad work)
Posted on 18 9 月 2012 by simon
对于刚学习seo的人来说,咋听说关键词密度的概念时会比较模糊,因为这比较抽象,无法具体化。
什么是关键词密度?
简单来说就是,你重复出现的关键词总文本长度占网页总文本长度的比例。
看如下的公式应该能明白
页面文本总长度:2149 字符
关键字符串长度:3 字符
关键字出现频率:34 次
关键字符总长度:102 字符
密度结果计算:4.7%
密度建议值:2%≦密度≦8%
chinaz站长工具是建议,在2%-8%之间,这个只是一个大概的建议范围,而在实际应用中往往不是如此。
关键词密度是一个模糊的概念而不是绝对。2-8%、3-7%、低于10%、5%左右这些都可以认为是正确的,我们在建站或者布词的时候,注意稍微增强一下关键词的密度,不用太刻意让页面的每个位置都出现关键词,那样也是得不偿失的。

