
Posted on 30 4 月 2014 by simon
啥是curl?请百度!
一款很强大的网页访问工具,curl是利用URL语法在命令行方式下工作的开源文件传输工具。它被广泛应用在Unix、多种Linux发行版中,并且有DOS和Win32、Win64下的移植版本。
选择一个适当的网页访问工具,往往是关系到一个软件的速度及稳定性。
测试的工具有:
易语言curl支持库、
http读文件(互联网支持库)、
WinInet方式、
WinHttpRequest 5.1对象方式
测试环境:
为避免网络波动影响测试,故本地搭建了IIS环境,网页大小425KB,为模拟真实页面,页面附加4个js文件,小图片28个,全部网页大小为925KB,全部本地化。
测试方式:
连续循环100次访问页面,测试每次耗费时间,取均值(ms)
易语言curl支持库:
* 93.000000
* 16.000000
* 15.000000
* 15.000000
* 16.000000
* 16.000000
* 15.000000
* 16.000000
* 15.000000
* 47.000000
******
均值:51.5ms、
http读文件:
* 7706.000000
* 312.000000
* 608.000000
* 328.000000
* 15.000000
* 16.000000
* 15.000000
* 302.000000
* 15.000000
******
均值:141.9ms
Continue Reading
Posted on 30 4 月 2014 by simon
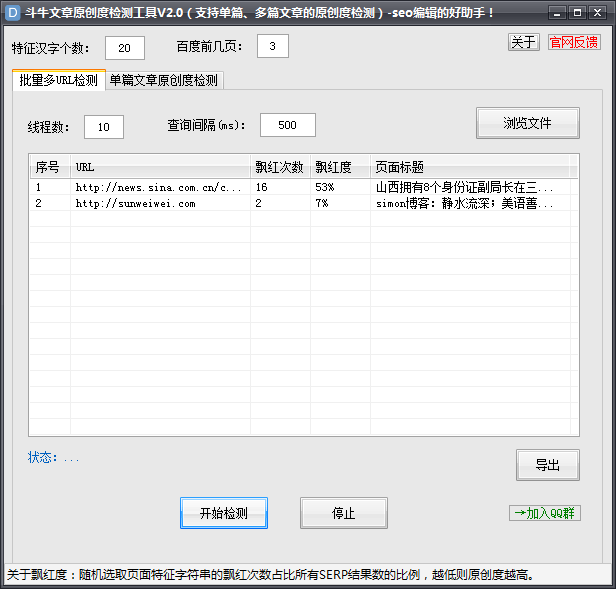
斗牛文章原创度检测工具V2.0 – 支持单篇文章、多篇文章的原创度检测,是编辑人员必备的SEO工具!
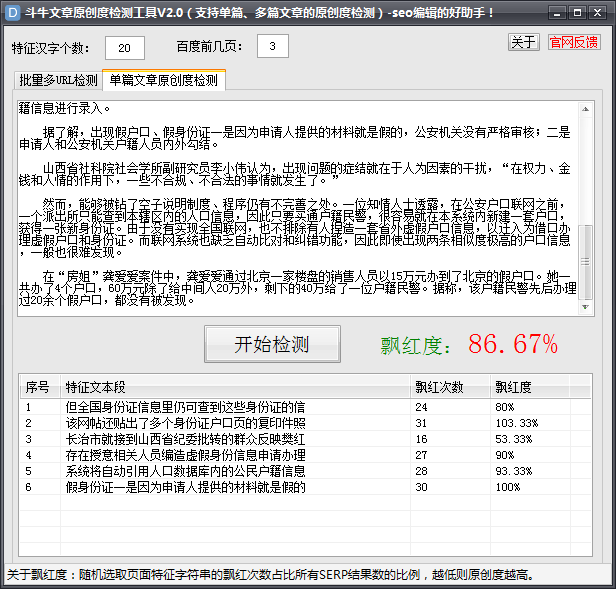
本工具主要用来检测文章的原创度,判别标准是:页面正文内随机选择连续的中文字符串在百度搜索结果页的飘红情况,提供飘红次数和飘红度数据,支持数据导出。
批量多URL检测是随机选择页面里一个汉字串进行检测;
而单篇文章检测是对所有汉字串进行检测!飘红度越小原创度越高。
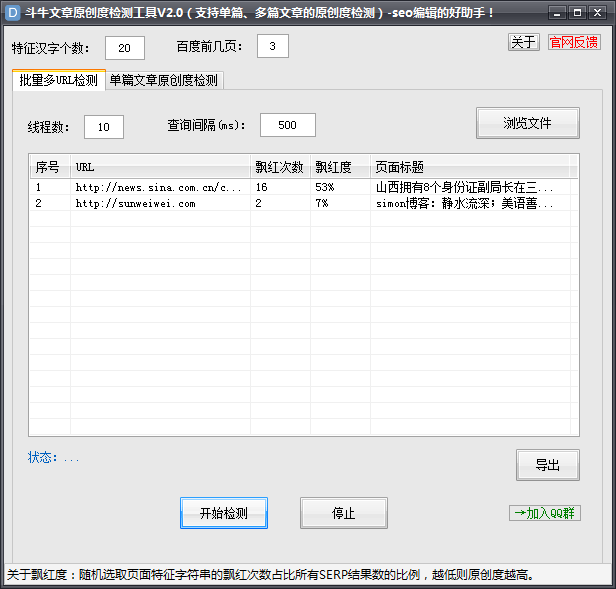
使用步骤:
1、将待检测的文章url地址放置在一个txt文本中,一行一个
2、可直接拖到文件至软件窗口,或者点击浏览按钮选择文件,只支持txt文件
3、开始运行即可。
软件功能:
1、支持多线程操作,线程数量可自己控制,默认10
2、支持查询间隔时间设定,默认500ms
3、支持设置查询百度前几页,默认前3页
4、支持页面随机选择的特征字符串汉字个数的设定,默认为20个汉字,可自己控制阀值。
5、遇验证码自动延时等待、自动恢复。
备注说明:
因为是随机选择页面正文的一段字符串,每次查询的原创度数据会有变化,自己控制好汉字个数。
Continue Reading
Posted on 09 4 月 2014 by simon
NLPIR汉语分词系统(官网:http://ictclas.nlpir.org/)
NLPIR汉语分词系统(又名ICTCLAS2014),主要功能包括中文分词;词性标注;命名实体识别;用户词典功能;支持GBK编码、UTF8编码、BIG5编码。新增微博分词、新词发现与关键词提取。
中科院的NLPIR分词系统应该是目前公认做的比较好的,支持自定义词典、支持批量分词、关键词提取、词性标注、文章指纹识别,2014版本添加了新词(未登录词)的识别等。
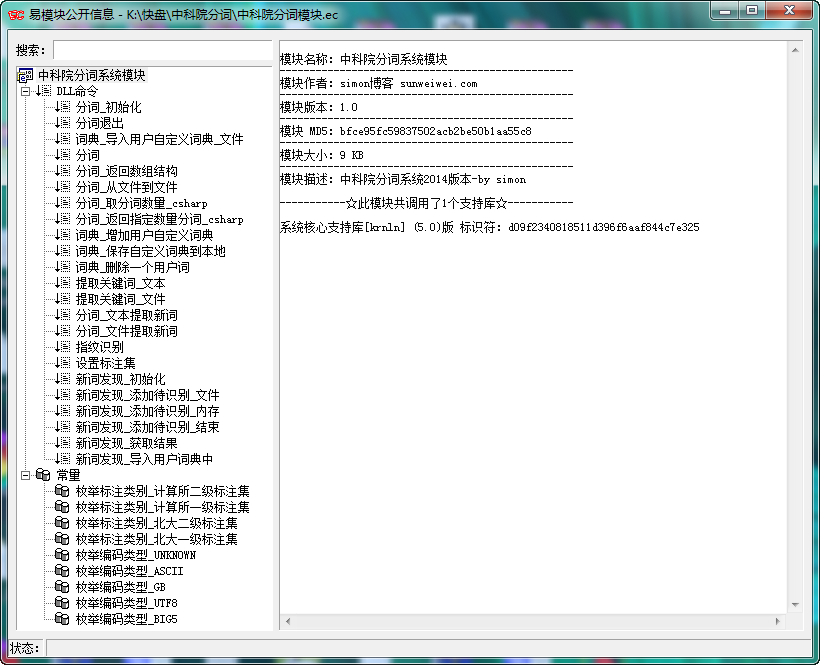
之前因为准备用里面的一个接口,找了一番发现其官方并没有提供易语言的api接口文档及源码示例。。。很多人对NLPIR分词系统还是很有需求的,所以制作了一个易语言的模块,封装了最新2014版的所有接口以供调用。
1、关键词提取接口:NLPIR_GetKeyWords()、NLPIR_GetFileKeyWords()这两个接口,分别为从文本中提取关键词和从文件中提取关键词,支持指定数量的提取和TF/IDF权重的输出,用来做tag标签啥的,比较合适。
2、指纹识别接口:NLPIR_FingerPrint()返回的貌似是一个多维度十六进制的向量,可以用在检测文章相似度上面,比如计算两篇文章指纹向量的余弦相似度;或者对采集的多个文件进行去重等等。而且这个分词系统支持多线程,大批量运行应该没太大问题。
3、新词识别接口:除自己定义的词典,此接口支持将识别到的新词自动导入到自定义词典中。里面新词识别接口有2个,建议使用后添加的NLPIR_NWI_Start() API.
4、关于用户词典和核心词典中同时有的分词词汇,谁优先? 可以在data/Configure.xml中设置
中科院分词模块.ec 下载地址: http://pan.baidu.com/s/1mgqMfrE 密码: h1a5
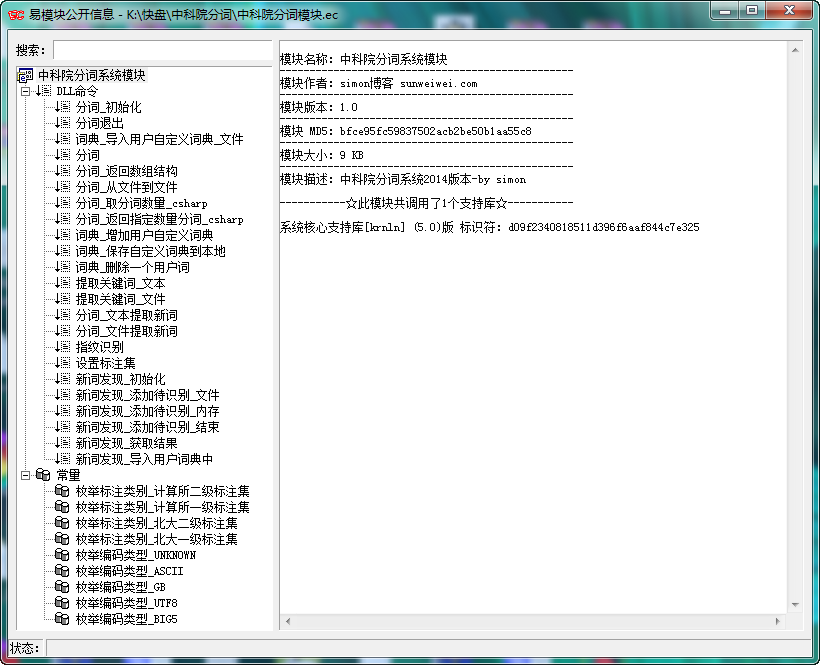
模块使用很简单:
1、去官方下载通用的NLPIR/ICTCLAS2014分词系统下载包(2014.3.24发布的),并解压到本地,只需要里面的NLPIR.dll(要找一下)和data目录文件即可
2、之后直接用易语言调用模块即可,如果不会用模块调用,请注意看模块里的每个参数说明,或查看官方的接口文档说明。


